PowerShell: Sorting and Encoding Problem
19 Aug 2017Recently I was working on processing a file of data and in order to deduplicate and sort it, I decided to employ Windows’ PowerShell scripting functionality. It’s a very powerful tool-set and perfectly suited to what I needed to do, but I ran afoul of a small detail that caused me some confusion at first but that I resolved in the end. Just in case anyone else comes upon such an issue I thought it might be useful to write up the problem and the simple solution.
Sorting and Deduplicating PowerShell
Given a file (foo.txt) it is fairly straightforward to process it to remove duplicates and alphabetically sort the lines into a new file (bar.txt). The PowerShell below will potentially do just that if run in the same directory as the source file.
Get-Content -Path foo.txt | sort | get-unique | Out-File bar.txt
It breaks down into four parts, separated by pipes (‘|’). The first gets the content of the file, the second sorts the content, the third removes duplicates and the fourth writes out the processed original content to a new file.
In many cases, this works fine. This included my original test data file that I manually created to check the script - the actual data file was over 70,000 lines and needed additional processing and so didn’t make a good test case for this one-liner.
The Problem
When I came to process the actual data file, the end result was not as I had expected. I’ve created some new data for this post that illustrates the issue.
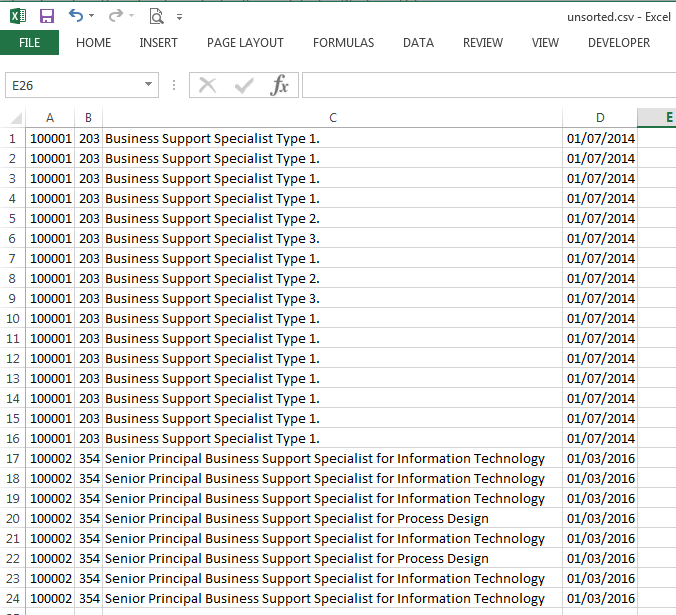
The file being processed was a CSV file and when opened in Excel (the default CSV editor on my PC), the fields in each row were displayed in separate columns.
The processed file however displayed each record within a single column. Double quotes and all.
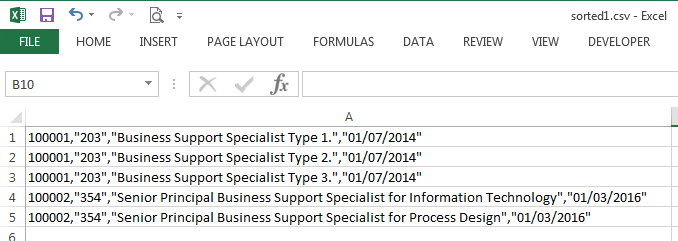
What was going on?
The Analysis
The output file looked just fine in my text editor, and I actually tried it in a few different ones just to be sure.

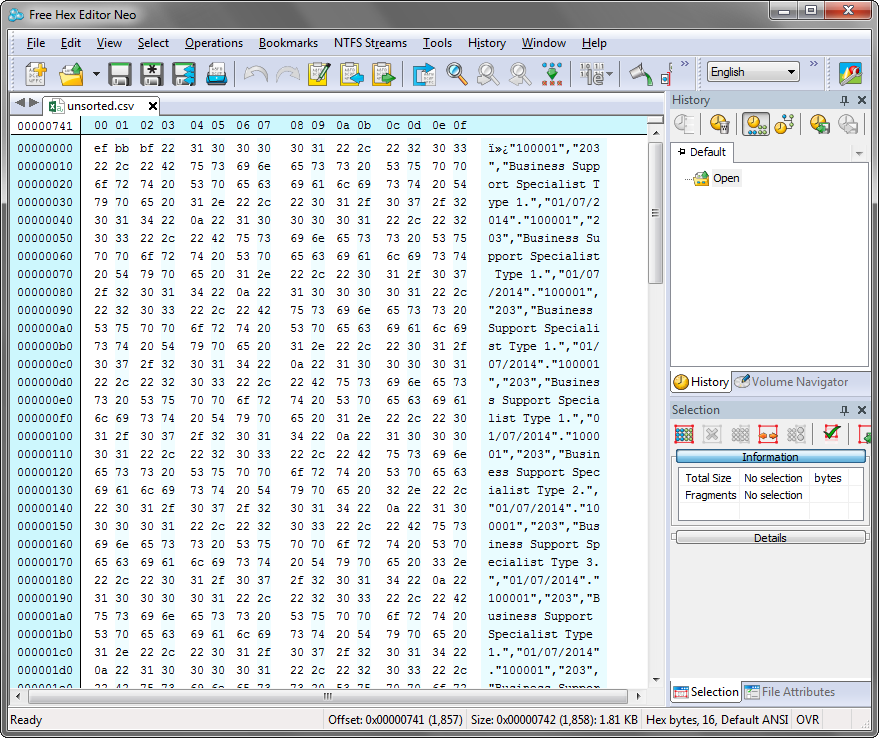
So why wasn’t Excel treating it like the CSV file it looked like? Well, the answer was that the text editors were showing an interpretation of the file and Excel was reading in the file in a more accurate way. This was evident from viewing the text file in a hex editor instead of a text editor.
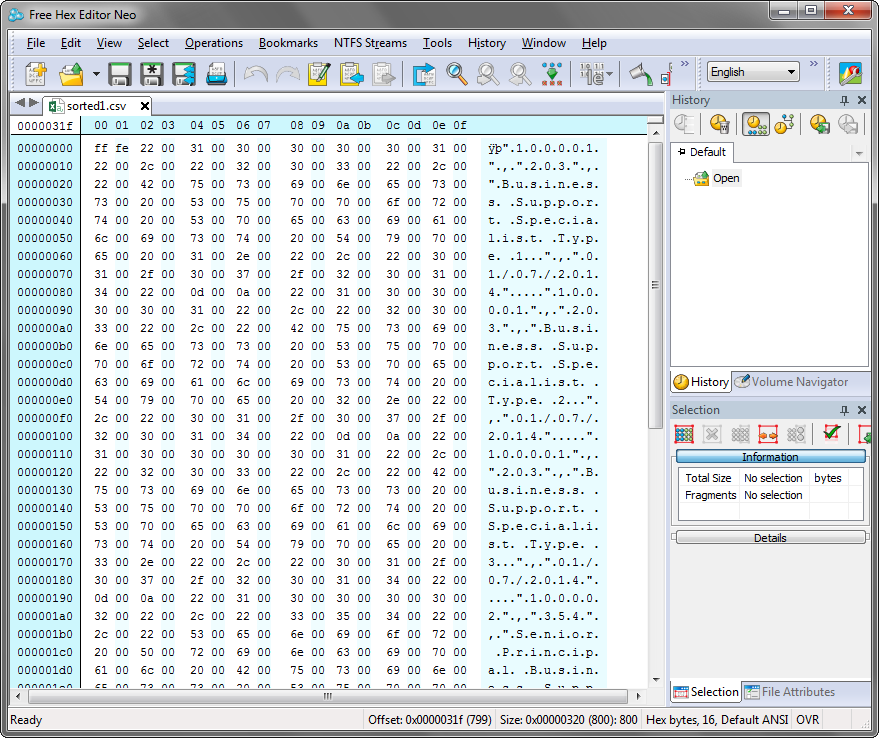
If you look at the data you can see empty bytes (00) being specified alongside each character. i.e. each character is a double byte. The text editors just ignored the first byte whereas Excel read them in and thus didn’t recognise the double quotes and commas; as a result, each line/record was displayed in a single field.
Opening the original unsorted file in the Hex editor, however, didn’t show any double-byte encoding and my original, manually created text file worked just fine. So what was going on? Why was the output file being created as a double-byte file?
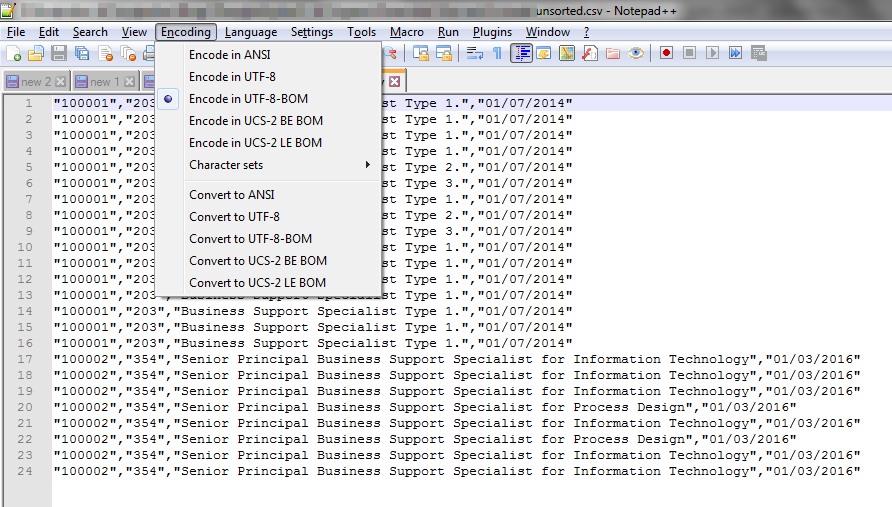
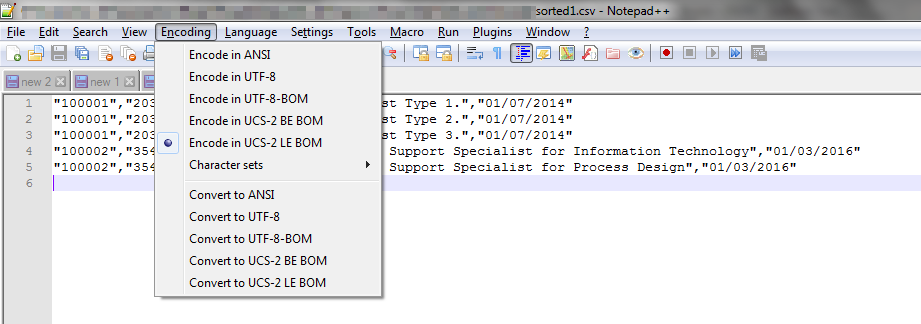
Well, this comes down to the encoding of the file. My test file was encoded using ANSI. The system producing the data file to be processed however was producing the file with UTF-8 BOM (8-bit Universal (character set) Transformation Format with Byte Order Mark) encoding. But the output file appeared to be producing a file encoding that was UCS-2 LE BOM (Universal Character Set 2 with Little Endian Byte Order Mark), a double-byte format.
NotePad++ allowed me to easily check the encoding of the files. Notably, my system generated data file and the resulting sorted and deduplicated file.
Executing the chcp (change code page) command at the Windows PowerShell prompt I got a return of “Active code page: 850”. This matches to “ibm850 - OEM Multilingual Latin 1; Western European (DOS)” … which as far as I know isn’t a double-byte encoding. Whilst this check and the PowerShell Out-File cmdlet documentation together suggest that this should be the output I think a something on my Windows 7 has really set it to UCS-2 (ref. Wikipedia - Code Page 850).
To find out more about encoding and the differences, take a look at this post on StackOverflow.
The Resolution
Tracking this down was rather convoluted, but fortunately, the solution is not anywhere near so convoluted. The Out-File cmdlet has an optional parameter that allows you to specify the encoding for the file. Here’s how it looks added to the end of the example PowerShell above.
Get-Content -Path foo.txt | sort | get-unique | Out-File bar.txt -Encoding UTF8
In this particular case, I chose UTF8 to allow for some potential extended characters (e.g. with diacritical marks) to be maintained. The resulting output formatted perfectly in Excel.
If you would like to take a look at this yourself and how it works on your PC (and version of Windows & PowerShell) then download the ZIP file below. Inside you’ll find copies of an unsorted file, two PowerShell scripts (version 1 without the encoding parameter and version 2 with the encoding parameter), the results files (which you can regenerate yourself) and a batch file that will run both of the scripts.
If you found this useful do let me know.